웹 캐시 : 자주 쓰이는 문서의 사본을 자동으로 보관하는 HTTP 장치
1. 불필요한 데이터 전송
- 복수의 클라이언트가 자주 쓰이는 원 서버 페이지에 접근할 때, 서버는 같은 문서를 클라이언트들에게 각각 한 번씩 전송하게 된다.
- 불필요한 데이터 전송은 값비싼 네트워크 대역폭을 잡아먹고, 전송을 느리게 만들며, 웹 서버에 부하를 준다.
- 캐시를 이용하면, 첫 번째 서버 응답은 캐시에 보관된다.
- 캐시 된 사본이 뒤이은 요청들에 대한 응답으로 사용될 수 있기 때문에, 원서버가 중복해서 트래픽을 주고받는 낭비가 줄어들게 된다.
2. 대역폭 병목

- 캐시는 네트워크 병목을 줄여준다.
- 많은 네트워크가 원격 서버보다 로컬 네트워크 클라이언트에 더 넓은 대역폭을 제공한다.
- 클라이언트들이 서버에 접근할 때의 속도는, 그 경로에 있는 가장 느린 네트워크의 속도와 같다
- 클라이언트가 빠른 LAN에 있는 캐시로부터 사본을 가져온다면, 캐싱은 성능을 대폭 개선할 수 있을 것이다
3. 갑작스런 요청 쇄도(Flash Crowds)

- 캐싱은 갑작스런 요청 쇄도에 대처하기 위해 특히 중요하다.
- 갑작스러운 사건(뉴스속보, 스팸메일 등)으로 초래된 불필요한 트래픽 급증은 네트워크와 웹 서버의 심각한 장애를 야기시킨다.
4. 거리로 인한 지연

- 대역폭이 문제가 되지 않더라도, 거리가 문제가 될 수 있다.
- 모든 네트워크 라우터는 제각각 인터넷 트래픽을 지연시킨다.
- 클라이언트와 서버 사이에 라우터가 그다지 많지 않더라도, 빛의 속도 그 자체가 유의미한 지연을 유발한다.
- 기계실 근처에 캐시를 설치해서 문서가 전송되는 거리를 수천 킬로미터에서 수 십 미터로 줄여 거리로 인한 지연을 줄일 수 있다.
5. 적중과 부적중

| 캐시 적중 | 캐시에 요청이 도착 했을 때 그에 대응하는 사본이 있어 그 사본으로 요청을 처리하는 경우 |
| 캐시 부적중 | 대응하는 사본이 없어 요청을 원 서버로 전달하게 되는 경우 |
| 캐시 재검사 적중 | 캐시가 신선한지 확인하고 원 서버에서 신선하다고 판단 했을 때 캐시에서 클라이언트로 사본을 보내는 경우 |
1. 재검사(Revalidation)

- 원 서버 콘텐츠는 변경될 수 있기 때문에, 캐시는 반드시 그들이 갖고 있는 사본이 여전히 최신인지 서버를 통해 때때로 점검하는데, 이것을 HTTP 재검사라고 한다.
- 효과적인 재검사를 위해, HTTP는 서버로부터 전체 객체를 가져오지 않고도 콘텐츠가 여전히 신선한지 빠르게 검사할 수 있는 특별한 요청을 정의했다.
- 그 사본이 검사를 할 필요가 있을 정도로 충분히 오래된 경우에만 재검사를 한다.
- 캐시는 캐시된 사본의 재검사가 필요할 때, 원 서버에 작은 재검사 요청을 보낸다.
- 콘텐츠가 변경되지 않았다면, 서버는 아주 작은 304 Not Modified 응답을 보낸다.
- 여전히 유효함을 알게 된 캐시는 즉각 사본이 선선하다고 임시로 다시 표시한 뒤 그 사본을 클라이언트에 제공
=> 재검사 적중, 느린 적중
속도 비교 : 캐시 적중 < 재검사 적중 < 캐시 부적중 - HTTP는 캐시된 객체를 재확인하기 위한 몇 가지 도구를 제공
- 가장 많이 쓰이는 것은 If-Modified-Since 헤더 => 캐시 된 시간 이후에 변경된 경우에만 사본을 보내달라는 의미
- 재검사 적중 => 서버는 클라이언트에게 작은 HTTP 304 Not Modified 응답
- 재검사 부적중 => 서버는 콘텐츠 전체와 함께 평범한 HTTP 200 OK 응답
- 객체 삭제 => 서버는 404 Not Found 응답을 돌려보내며, 캐시는 사본을 삭제
- 가장 많이 쓰이는 것은 If-Modified-Since 헤더 => 캐시 된 시간 이후에 변경된 경우에만 사본을 보내달라는 의미
2. 적중률
적중률(혹은 문서 적중률) : 캐시가 요청을 처리하는 비율
- 오늘날 적중률 40%면 웹 캐시로 괜찮은 편
- 보통 크기의 캐시라도 충분한 분량의 자주 쓰이는 문서들을 보관하여 상당히 트래픽을 줄이고 성능을 개선할 수 있다
- 캐시는 유용한 콘텐츠가 캐시 안에 머무르도록 보장하기 위해 노력한다.
3. 바이트 적중률
바이트 적중률 : 캐시를 통해 제공된 모든 바이트의 비율을 표현
- 바이트 적중률은 트래픽이 절감된 정도를 포착
- 문서 적중률과 바이트 단위 적중률은 둘 다 캐시 성능에 대한 유용한 지표
- 문서 적중률은 얼마나 많은 웹 트랜잭션을 외부로 내보내지 않았는지 보여준다.
=> 전체 대기시간(지연)이 줄어든다. - 바이트 단위 적중률은 얼마나 많은 바이트가 인터넷으로 나가지 않았는지 보여준다.
=> 대역폭 절약을 최적화
4. 적중과 부적중의 구별
- HTTP는 클라이언트에게 응답이 캐시 적중이었는지 아니면 원 서버 접 인지 말해줄 수 있는 방법을 제공하지 않는다.
- 클라이언트가 응답이 캐시에서 왔는지 알아내는 한 가지 방법은 Date 헤더를 이용하는 것
- 응답의 Date 헤더 값을 현재 시각과 비교하여, 응답의 생성일이 더 오래되었다면 클라이언트는 응답이 캐시 된 것
- 또 다른 방법은, 응답이 얼마나 오래되었는지 말해주는 Age 헤더를 이용하는 것
6. 캐시 토폴로지
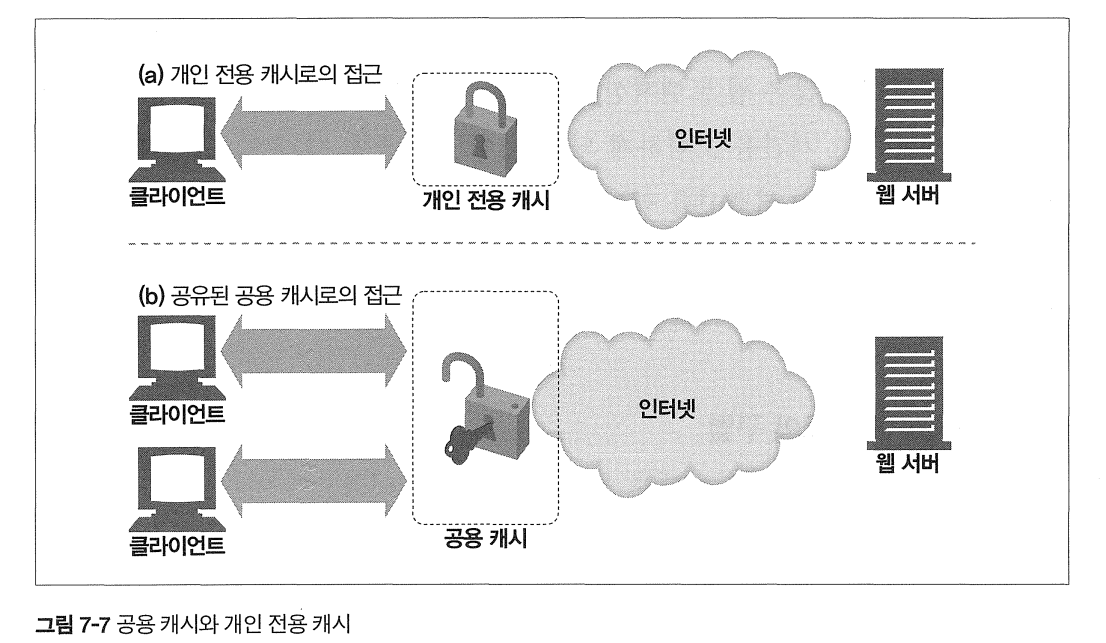
개인 전용 캐시 : 한 명에게만 할당된 캐시
공용 캐시 : 공유된 캐시
1. 개인 전용 캐시
- 많은 에너지나 저장 공간을 필요로 하지 않으므로, 작고 저렴할 수 있다.
- 웹 브라우저는 개인 전용 캐시를 내장하고 있다.
- 자주 쓰이는 문서를 개인용 컴퓨터의 디스크와 메모리에 캐시
- 사용자가 캐시 사이즈와 설정을 수정할 수 있도록 허용
2. 공용 프락시 캐시
- 캐시 프락시 서버 혹은 더 흔히 프락시 캐시라고 불리는 특별한 종류의 공유된 프락시 서버
- 프락시 캐시는 로컬 캐시에서 문서를 제공하거나 혹은 사용자의 입장에서 서버에 접근
- 공용 캐시에는 여러 사용자가 접근하기 때문에, 불필요한 트래픽을 줄일 수 있는 더 많은 기회가 있다.
3. 프락시 캐시 계층들

- 작은 캐시에서 캐시 부적중이 발생했을 때, 더 큰 부모 캐시가 ‘걸러 남겨진’ 트래픽을 처리하도록 하는 계층을 만드는 방식이 합리적인 경우가 많다.
- 프락시 연쇄가 길어질수록 각 중간 프락시는 현저한 성능 저하가 발생할 것
4. 캐시망, 콘텐츠 라우팅, 피어링

- 몇몇 네트워크 아키텍처는 단순한 캐시 계층 대신 복잡한 캐시 망을 만든다.
- 캐시망의 프락시 캐시는 복잡한 방법으로 서로 대화하여 요청의 이동 방향을 동적으로 결정한다.
- 이러한 복잡한 캐시 사이의 관계는, 서로 다른 조직들이 상호 이득을 위해 그들의 캐시를 연결하여 서로를 찾아볼 수 있도록 해준다.
- 선택적인 피어링을 지원하는 캐시는 형제 캐시
- HTP는 형제 캐시를 지원하지 않기 때문에, 사람들은 인터넷 캐시 프로토콜(ICP)이나 하이퍼텍스트 캐시 프로토콜 (HTCP) 같은 프로토콜을 이용해 HTTP를 확장했다.
7. 캐시 처리 단계

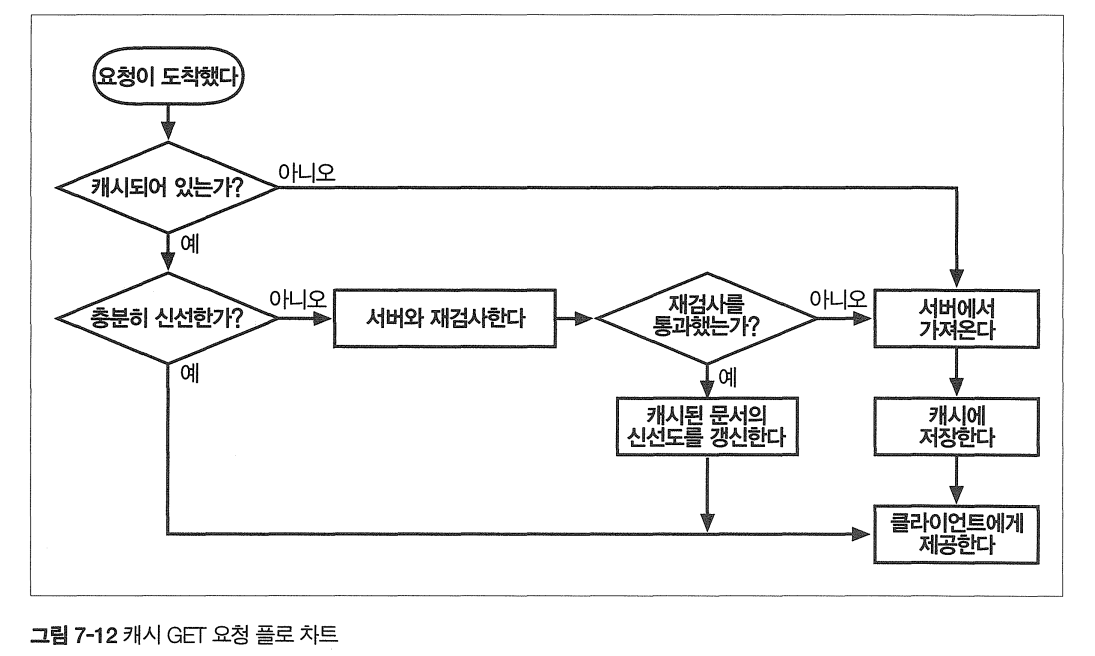
- HTTP GET 메시지 하나를 처리하는 기본적인 캐시 처리 절차는 일곱 단계로 이루어져 있다.
- 요청받기 - 캐시는 네트워크로부터 도착한 요청 메시지를 읽는다.
- 파싱 - 캐시는 메시지를 파싱 하여 URL과 헤더들을 추출한다.
- 검색 - 캐시는 로컬 복사본이 있는지 검사하고, 사본이 없다면 사본을 받아온다(그리고 로컬에 저장한다).
- 선선도 검사 - 캐시는 캐시된 사본이 충분히 신선한지 검사하고, 선선하지 않다면 변경사항이 있는지 서버에게 물어본다.
- 응답 생성 - 캐시는 새로운 헤더와 캐시 된 본문으로 응답 메시지를 만든다.
- 발송 - 캐시는 네트워크를 통해 응답을 클라이언트에게 돌려준다.
- 로깅 - 선택적으로, 캐시는 로그파일에 트랜잭션에 대해 서술한 로그 하나를 남긴다.
1. 단계 1: 요청 받기
- 캐시는 네트워크 커넥션에서의 활동을 감지하고, 들어오는 데이터를 읽어 들인다.
- 고성능 캐시는 여러 개의 들어오는 커넥션들로부터 데이터를 동시에 읽어 들이고 메시지 전체가 도착하기 전에 트랜잭션 처리를 시작
2. 단계 2: 파싱
- 캐시는 요청 메시지를 여러 부분으로 파싱 하여 헤더 부분을 조작하기 쉬운 자료구조에 담는다.
=> 캐싱 소프트웨어가 헤더 필드를 처리하고 조작하기 쉽게 만들어준다.
3. 단계 3: 검색
- 캐시는 URL을 알아내고 그에 해당하는 로컬 사본이 있는지 검사한다.
- 전문적인 수준의 캐시는 객체를 로컬 캐시에서 가져올 수 있는지 판단하기 위해 빠른 알고리즘을 사용
- 문서를 로컬에서 가져올 수 없다면, 캐시는 상황이나 설정에 따라서 원 서버나 부모 프락시에서 가져오거나 실패를 반환한다.
- 캐시 된 객체는 서버 응답 본문과 원 서버 응답 헤더를 포함하고 있으므로, 캐시 적중 동안 올바른 서버 헤더가 반환될 수 있다.
4. 단계 4: 신선도 검사
- HTTP는 캐시가 일정 기간 동안 서버 문서의 사본을 보유할 수 있도록 해준다.
- 캐시 된 사본을 선선도 한계를 넘을 정도로 너무 오래 갖고 있었다면 그 객체는 ‘신선하지 않은’ 것으로 간주된다.
- 캐시는 그 문서를 제공하기 전에 문서에 어떤 변경이 있었는지 검사하기 위해 서버와 재검사를 해야 한다.
5. 단계 5: 응답 생성
- 캐시는 캐시 된 서버 응답 헤더를 토대로 응답 헤더를 생성
- 캐시는 클라이언트에 맞게 이 헤더를 조정해야 하는 책임이 있다.
- 요청이 프락시 캐시를 거쳐갔음을 알려주기 위해 종종 Via 헤더를 포함
- 캐시가 Date 헤더를 조정해서는 안 된다
6. 단계 6: 전송
- 응답 헤더가 준비되면, 캐시는 응답을 클라이언트에게 돌려준다.
7. 단계 7: 로깅
- 대부분의 캐시는 로그 파일과 캐시 사용에 대한 통계를 유지한다.
- 캐시 트랜잭션이 완료된 후, 캐시는 통계 캐시 적중과 부적중 횟수에 대한 통계를 갱신하고 로그 파일에 요청 종류, URL 그리고 무엇이 일어났는지를 알려주는 항목을 추가
- 가장 많이 쓰이는 캐시 로그 포맷은 스퀴드 로그 포맷, 넷스케이프 확장 공용 로그 포맷
- 많은 캐시 제품이 커스텀 로그 파일을 허용
8. 캐시 처리 플로 차트
8. 사본을 신선하게 유지하기
- 캐시된 사본 모두가 서버의 문서와 항상 일치하는 것은 아니다.
- 캐시된 데이터는 서버의 데이터와 일치하도록 관리되어야 한다.
- HTTP는 어떤 캐시가 사본을 갖고 있는지 서버가 기억하지 않더라도, 캐시 된 사본이 서버와 충분히 일치하도록 유지할 수 있게 해주는 단순한 메커니즘을 갖고 있다.
1. 문서 만료

- HTTP는 Cache-Control과 Expires라는 특별한 헤더들을 이용해서 원 서버가 각 문서에 유효기간을 붙일 수 있게 해 준다.
- 일단 캐시 된 문서가 만료되, 캐시는 반드시 서버와 문서에 변경된 것이 있는지 검사해야 하며, 만약 그렇다면 신선한 사본을 얻어 와야 한다
2. 유효기간과 나이

3. 서버 재검사
- 캐시된 문서가 만료되었다는 것은, 그 문서가 원 서버에 현재 존재하는 것과 실제로 다르다는 것을 의미하지는 않으며, 다만 이제 검사할 시간이 되었음을 뜻한다.
- 재검사 결과 콘텐츠가 변경되었다면 캐시는 그 문서의 새로운 사본을 가져와 오래된 데이터 대신 저장한 뒤 클라이언트에게도 보내준다.
- 재검사 결과 콘텐츠가 변경되지 않았다면, 캐시는 새 만료일을 포함한 새 헤더들만 가져와서 캐시 안의 헤더들을 갱신한다.
4. 조건부 메서드와의 재검사
- HTTP의 조건부 메서드는 재검사를 효율적으로 만들어준다.
- HTTP는 캐시가 서버에게 ‘조건부 GET’이라는 요청을 보낼 수 있도록 해준다.
=> 서버가 갖고 있는 문서가 캐시가 갖고 있는 것과 다른 경우에만 객체 본문을 보내달라고 하는 것 - HTTP는 다섯 가지 조건부 요청 헤더를 정의한다.(가장 유용한 두 개는 If-Modified-Since와 If-None-Match)

5. If-Modified-Since: 날짜 재검사

- If-Modified-Since 재검사 요청은 흔히 ‘IMS’ 요청으로 불린다.
- IMS 요청은 서버에게 리소스가 특정 날짜 이후로 변경된 경우에만 요청한 본문을 보내달라고 한다.
- If-Modfied-Since 헤더는 서버 응답 헤더의 Last-Modified 헤더와 함께 동작
- 몇몇 웹 서버는 If-Modified-Since를 실제 날짜 비교로 구현하지 않고, IMS 날짜와 최근 변경일 간의 문자열 비교를 수행한다.
6. If-None-Match: 엔터티 태그 재검사
- 문서를 변경했을 때, 문서의 엔터티 태그를 새로운 버전으르 표현할 수 었다.
- 엔터티 태그가 변경되었다면, 캐시는 새 문서의 사본을 얻기(GET) 위해 If-None-Match 조건부 헤더를 사용할 수 었다.
- 캐시가 객체에 대한 여러 개의 사본을 갖고 있는 경우, 그 사실을 서버에게 알리기 위해 하나의 If-None-Match 헤더에 여러 개의 엔터티 태그를 포함시킬 수 있다.
7. 약한 검사기와 강한 검사기
- HTTP/1.1은 비록 콘텐츠가 조금 변경되었더라도 “그 정도면 같은 것”이라고 서버가 주장할 수 있도록 해주는 ‘약한 검사기’를 지원
- 강한 검사기는 콘텐츠가 바뀔 때마다 바뀐다.
- 조건부 특정 범위 가져오기 같은 몇몇 동작은 약한 검사기로는 불가능하기 때문에 서버는 'w/’ 접두사로 약한 검사기를 구분
8. 언제 엔터티 태그를 사용하고 언제 Last-Modified 일시를 사용하는가
- HTTP/1.1 클라이언트는 만약 서버가 엔터티 태그를 반환했다면, 반드시 엔터티 태그 검사기를 사용해야 한다.
- 서버가 Last-Modified 값만을 반환했다면, 클라이언트는 표 Modified-Since 검사를 사용할 수 있다.
9. 캐시 제어
1. no-cache와 no-store 응답 헤더
- no-store와 no-cache 헤더는 캐시가 검증되지 않은 캐시 된 객체로 응답하는 것을 막는다.
- no-store가 표시된 응답은 캐시가 그 응답의 사본을 만드는 것을 금지
=> 먼저 서버와 재검사를 하지 않고서는 캐시에서 클라이언트로 제공될 수 없다는 의미 - 클라이언트에게 no-store 응답을 전달하고 나면 객체를 삭제할 것
2. Max-Age 응답 헤더
- Cache-Control: max-age 헤더는 선선하다고 간주되었던 문서가 서버로부터 온 이후로 흐른 시간이고, 초로 나타낸다.
- 서버는 최대 나이먹음(maximum aging)을 0으로 설정함으로써 캐시가 매 접근마다 문서를 캐시 하거나 리프레시하지 않도록 요청할 수 있다.
3. Expires 응답 헤더
- HTTP를 설계한 사람들은, 많은 서버가 동기화되어 있지 않거나 부정확한 시계를 갖고 있기 때문에 만료를 절대 시각 대신 경과된 시간으로 표현하는 것이 낫다고 판단
- 신선도 수명의 근삿값은 만료일과 생성일의 초 단위 시간차를 계산하여 얻을 수 있다.
4. Must-Revalidate 응답 헤더
- Cache-Control: must-revalidate 응답 헤더는 캐시가 이 객체의 신선하지 않은 사본을 원 서버와의 최초의 재검사 없이는 제공해서는 안 됨을 의미
- 신선도 검사를 시도했을 때 원 서버가 사용할 수 없는 상태라면, 캐시는 반드시 504 Gateway Timeout error를 반환
'HTTP 완벽가이드' 카테고리의 다른 글
| 9. 웹 로봇 (0) | 2022.08.15 |
|---|---|
| 6. 프락시 (0) | 2022.08.10 |
| 5. 웹서버 (0) | 2022.08.06 |
| 1장 - HTTP 개관 (0) | 2022.07.24 |



